




📖 この記事で分かること
- Qwen3-TTSは3秒の音声から声をクローンできるAIモデル
- 商用サービスを上回る性能がApache 2.0で無料公開
- 10言語対応でローカルPCでも動作可能
- 日本語品質が従来のオープンソースTTSを大きく上回る
💡 知っておきたい用語
- ボイスクローン:短い音声サンプルをAIに聞かせて、その人の声で別のテキストを読み上げさせる技術。声の「コピー機」のようなもの。
最終更新日: 2026年1月24日
Qwen3-TTSとは何か
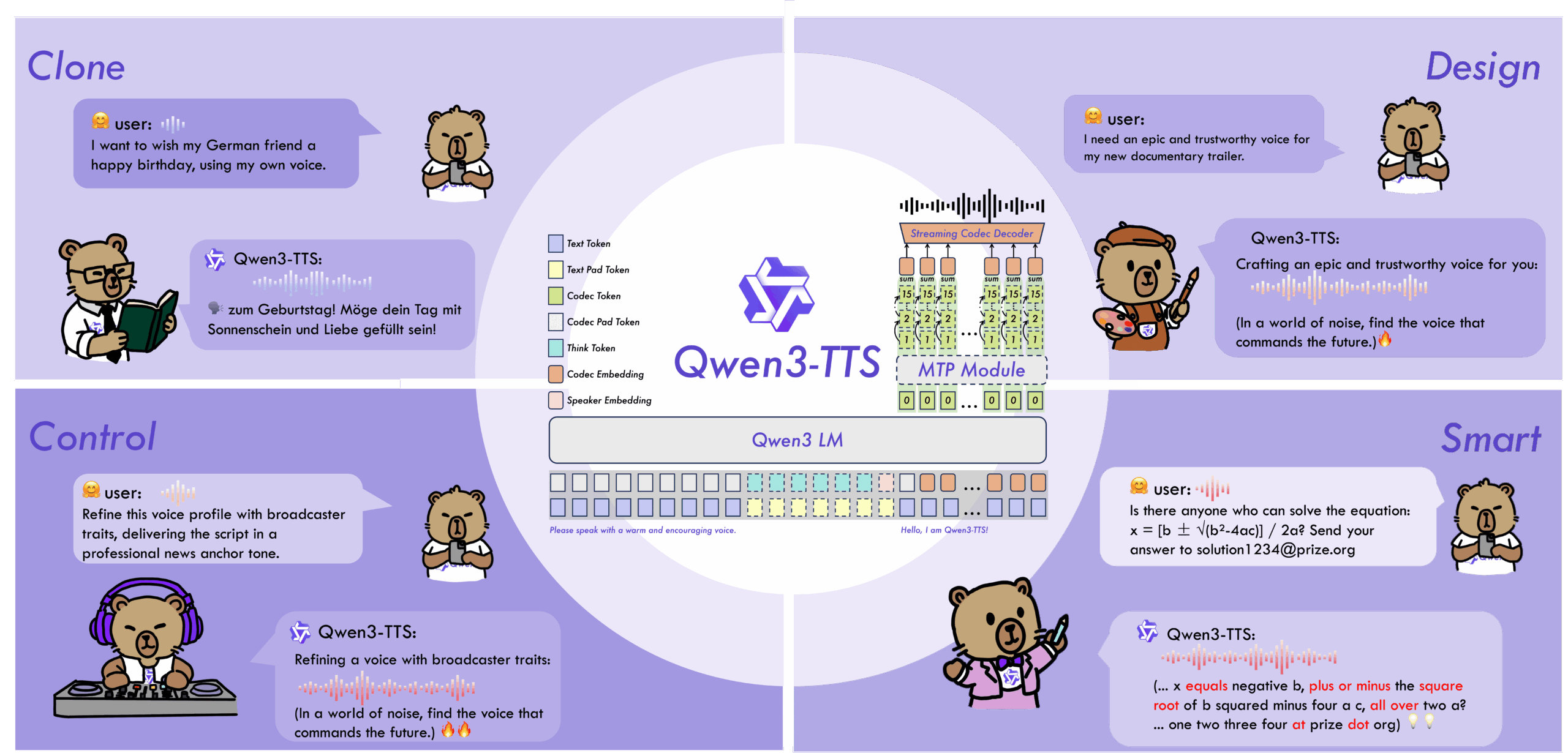
Alibaba CloudのQwenチームが開発した音声生成AIモデルで、2026年1月22日にオープンソース公開されました。最大の特徴は、わずか3秒の音声サンプルからその人の声をクローンできることです。従来のボイスクローン技術では数十分から数時間の録音が必要でしたが、Qwen3-TTSはこの障壁を大幅に引き下げました。
モデルは0.6B(6億パラメータ)と1.7B(17億パラメータ)の2サイズで提供されています。Apache 2.0ライセンスのため、商用利用も可能です。GitHub、Hugging Face、ModelScopeから無料でダウンロードできます。
対応言語は中国語、英語、日本語、韓国語、ドイツ語、フランス語、ロシア語、ポルトガル語、スペイン語、イタリア語の10言語です。中国語については広東語や四川語など9種類の方言もサポートしています。
技術的な特徴と性能
Qwen3-TTSは独自開発の「Qwen3-TTS-Tokenizer-12Hz」を採用しています。このトークナイザーは音声信号を効率的に圧縮しながら、声質や感情といった非言語情報を保持します。初回パケット遅延は約97msと、リアルタイム対話にも対応できる低遅延を実現しました。
ベンチマーク性能では、MiniMax TTS多言語テストセットにおいて、10言語中6言語(中国語、英語、イタリア語、フランス語、韓国語、ロシア語)で最低のWER【ワードエラーレート】を達成しています。平均WERは1.835%、話者類似度は0.789と、商用サービスのMiniMaxやElevenLabsを上回る結果が報告されています。
連続生成は10分以上に対応しており、オーディオブックやポッドキャストといった長尺コンテンツにも適しています。訓練データは500万時間以上の音声データが使用されました。
モデルは3種類の用途別バリエーションがあります。
- Base: 音声サンプルからのボイスクローン用。最も広く使われている
- VoiceDesign: 「20代女性、少し甘えた感じ」といったテキスト指示だけで新しい声を生成
- CustomVoice: 9種類のプリセット音声から選択し、スタイル調整が可能
競合サービスとの比較
現時点でボイスクローン市場をリードしているのはElevenLabsです。高品質な音声生成と使いやすいAPIで多くの開発者に採用されています。ただし、クラウドベースのサービスであり、従量課金制(Pro版で月額99ドル、50万文字まで)となっています。
MiniMaxは中国発のサービスで、以前は日本語品質で高い評価を得ていました。こちらも商用利用には料金が発生します。
Qwen3-TTSの優位点は以下の3つです。第一に、完全無料でオープンソースであること。第二に、ローカル環境で動作するためデータを外部に送信する必要がないこと。第三に、ベンチマーク性能で商用サービスを上回っていることです。
一方で課題もあります。NVIDIA GPU(0.6Bモデルで8GB未満、1.7Bモデルで約16GB VRAM)が推奨されており、Mac環境での動作は限定的との報告があります。また、英語音声が「アニメ声っぽい」という指摘もHacker Newsなどで見られます。
導入方法と注意点
試用の最も簡単な方法は、Hugging Faceの公式デモ(https://huggingface.co/spaces/Qwen/Qwen3-TTS)を使うことです。ブラウザ上でボイスクローン、音声デザイン、カスタムボイスの各機能を試せます。
ローカル環境で動かす場合は、GitHubリポジトリ(https://github.com/QwenLM/Qwen3-TTS)からモデルをダウンロードします。Pythonパッケージ「qwen-tts」をインストールすれば、数行のコードで音声生成が可能です。Flash Attention対応のNVIDIA GPUが推奨されています。
Alibaba Cloud経由でAPIを利用する場合、開発者向けに100万文字の無料枠が提供されています。49種類のプリセット音声も利用可能です。
倫理面では、他人の声を無断でクローンしないこと、なりすまし目的での使用を避けることが重要です。ボイスクローン技術は詐欺やディープフェイクに悪用されるリスクがあり、利用者の責任ある判断が求められます。
日本語コミュニティでは「自分の声すぎて怖いレベル」「息の入り方まで再現されている」といった反応が見られます。一方で「長文だと変な間や読み間違いが出ることがある」という指摘もあり、用途によっては手動での確認・修正が必要になる可能性があります。
よくある質問
Q: Qwen3-TTSは商用利用できますか?
A: はい、Apache 2.0ライセンスで公開されているため、商用利用が可能です。ただし、他人の声を無断でクローンして商用利用することは法的・倫理的な問題が生じる可能性があります。
Q: MacやCPUだけでも動かせますか?
A: 公式ドキュメントはNVIDIA GPU(CUDA対応)を推奨しています。Macでの動作報告もありますが、公式にはサポートされていません。CPUのみでの実行は処理速度が大幅に低下する可能性があります。
Q: 日本語の品質は実用レベルですか?
A: ベンチマーク上は他の商用サービスと競合する水準にあります。日本語コミュニティでは高評価が多いですが、長文生成時に不自然な間が入るケースも報告されています。実際に試用して用途に合うか確認することをおすすめします。
まとめ
Qwen3-TTSは、3秒の音声から声をクローンできるオープンソースTTSモデルです。商用サービスを上回るベンチマーク性能をApache 2.0ライセンスで無料提供しており、ローカル実行によるプライバシー保護も可能です。日本語品質の高さから国内でも注目を集めていますが、長文生成時の安定性やNVIDIA GPU推奨といった制約もあります。ポッドキャスト、オーディオブック、ゲームNPCなど、音声コンテンツ制作のコストを大幅に下げる可能性を持つ技術です。
【用語解説】
- TTS【ティーティーエス】: Text-to-Speechの略。テキストを音声に変換する技術のこと。
- WER【ワードエラーレート】: 音声認識や音声合成の精度を測る指標。生成された音声を再度文字起こしした際の誤り率を示す。低いほど高精度。
- Apache 2.0ライセンス【アパッチ ニーテンゼロ ライセンス】: オープンソースライセンスの一種。商用利用や改変が許可されており、著作権表示を残せば自由に使える。
免責事項: 本記事の情報は執筆時点のものです。AI技術は急速に進歩しているため、機能や制限は予告なく変更される場合があります。
引用元:
- [1] GitHub QwenLM/Qwen3-TTS – https://github.com/QwenLM/Qwen3-TTS
- [2] Qwen3-TTS Technical Report (arXiv) – https://arxiv.org/html/2601.15621v1
- [3] Hugging Face Qwen Collection – https://huggingface.co/collections/Qwen/qwen3-tts
- [4] Alibaba Cloud Model Studio – https://www.alibabacloud.com/help/en/model-studio/qwen-tts
- [5] The Decoder – https://the-decoder.com/alibabas-new-qwen-models-can-clone-voices-from-three-seconds-of-audio/
Previous Post
SlackやDiscordから自宅PCを操作——「Clawdbot」が実現するAI執事


Next Post
【NotebookLM】キャラクター付きスライド生成を実験してみた!

15年以上の開発経験を持つソフトウェアエンジニア。クラウドやWeb技術に精通し、業務システムからスタートアップ支援まで幅広く手掛ける。近年は、SaaSや業務システム間の統合・連携開発を中心に、企業のDX推進とAI活用を支援。
技術だけでなく、経営者やビジネスパーソンに向けた講演・執筆を通じて、生成AIの最新トレンドと実務への落とし込みをわかりやすく伝えている。
また、音楽生成AIのみで構成したDJパフォーマンスを企業イベントで展開するなど、テクノロジーと表現の融合をライフワークとして探求している。









