





Jan 12 2026
【NotebookLM活用事例】初心者向け文字起こし整形術|会議の生音声データを整形するコツ
皆さん、こんにちは。
NotebookLM(ノートブック・エルエム)で会議の音声データをアップロードすると、自動で文字起こしが作られて便利ですよね。
でも、実際にその文字起こしをそのまま読もうとすると、こんな悩みが出てきませんか?
- 誤字脱字が多くて読みづらい
- 誰が何を言ったのか分からない
- 商品名や社内用語が変な変換になっている
私もNotebookLMを使い始めた頃、「文字起こしはできたけど、これ、そのまま議事録として使えないな…」と感じていました。
そこで今回は、私が普段行っているNotebookLMで作った「生の文字起こし」を、読みやすく整形して「使える文字起こし」に変える具体的な方法を解説していきたいと思います。
なお、音声データから文字起こしを作る基本的な手順については、過去記事で詳しく解説していますので、そちらをご覧ください。 ⇛ 最速30秒!NotebookLMで音声ファイルを一撃文字起こしする方法
本記事では、その続きとして「できあがった文字起こしをどう整えるか」に焦点を当てていきます。
1. NotebookLM文字起こし整形術の基本プロンプト
では早速、会議の文字起こしを例に、「生テキスト」を整形する具体的なやり方を見ていきましょう。
1-1. まずは「誤字脱字と句読点」を整える
「NotebookLMって、文字起こしは自動でやってくれるけど、整形もできるの?」
と思われた方もいらっしゃるかもしれませんね。
実は、NotebookLMのチャット機能を使えば、文字起こしの「整形」も簡単にできます。
やり方はこうです。
- NotebookLMのチャット画面を開く
- 対象の音声ソース(会議録のトランスクリプト)を選択
- 次のようにプロンプトを書いて送信する
プロンプト例:
この会議の文字起こしを、内容を変えずに整形してください。
- 誤字脱字の修正
- 不自然な改行の修正
- 必要な箇所への句読点の追加
を行い、要約はせず、情報を削らないでください。ここで大事なポイントが3つあります。
- 「内容を変えない」
- 「要約しない」
- 「情報を削らない」
この3つを明示しないと、NotebookLMは「要約が得意」なので、勝手に内容を短くまとめてしまうことがあるんですね。
ですから、「整形だけしてほしい」ときは、必ずこの条件を付けてあげると良いと思います。
1-2. 会議なら「参加者情報」を教えて話者ラベルを付ける
さて、会議の文字起こしで一番困るのが、「誰が何を言ったか分からない」問題ですよね。
NotebookLMは、声そのものを識別しているわけではありません。
ただ、「発言内容」から話者をある程度推測してもらうことは可能です。
これを活用するために、整形の前後どちらでもいいので、次のような情報をNotebookLMに伝えてあげましょう。
プロンプト例:
この会議の参加者は以下の3名です。
- 佐藤:プロダクトマネージャー
- 鈴木:バックエンドエンジニア
- 田中:デザイナー
可能な範囲で、発言内容から誰の発言か推測し、各発言の先頭に「佐藤:」「鈴木:」「田中:」のように話者ラベルを付けてください。
内容を変えず、要約はしないでください。もちろん、100%正確というわけではありません。
ただ、私の経験では、
- 明らかに「エンジニアっぽい発言」はエンジニアに
- デザインの話はデザイナーに
といった形で、かなり実用的なレベルでラベルを振ってくれるケースが多いんですね。
重要な会議では、最後に人間がざっとチェックする前提で使うと良いと思います。
1-3. 商品名・社内用語など「独自の単語」を事前に教える
会議やインタビューでは、プロダクト名や社内ツール名など、一般的な辞書にない単語がたくさん出てきますよね。
これが誤変換されると、後から読み返すときにかなりストレスになります。
そこで、整形のプロンプトに「用語リスト」を添えておくと、NotebookLMが表記を揃えてくれやすくなるわけです。
プロンプト例:
この会議では、以下の固有名詞が出てきます。誤変換されている場合は、次の表記に統一してください。
- プロダクト名:NURA
- 社内ツール:X-Board
- クライアント名:ABC社
先ほどの条件(誤字脱字の修正・句読点の追加・要約しない)もあわせて適用してください。この一手間を入れておくだけで、後から検索しやすい「きれいなテキスト」ができあがります。
特にDX(デジタルトランスフォーメーション)やAI関連のプロジェクトでは、専門用語が多いので、この方法は宝の持ち腐れにならないよう、ぜひ活用していただきたいと思います。
2. 整形後の文字起こしをソース化して再利用する
さて、ここまでで文字起こしの整形ができましたね。
でも、ここで終わってしまうのはもったいないんです。
NotebookLMの強みは、「ソースとして再利用できること」ですから、ここまでやっておくと、後々かなり楽になります。
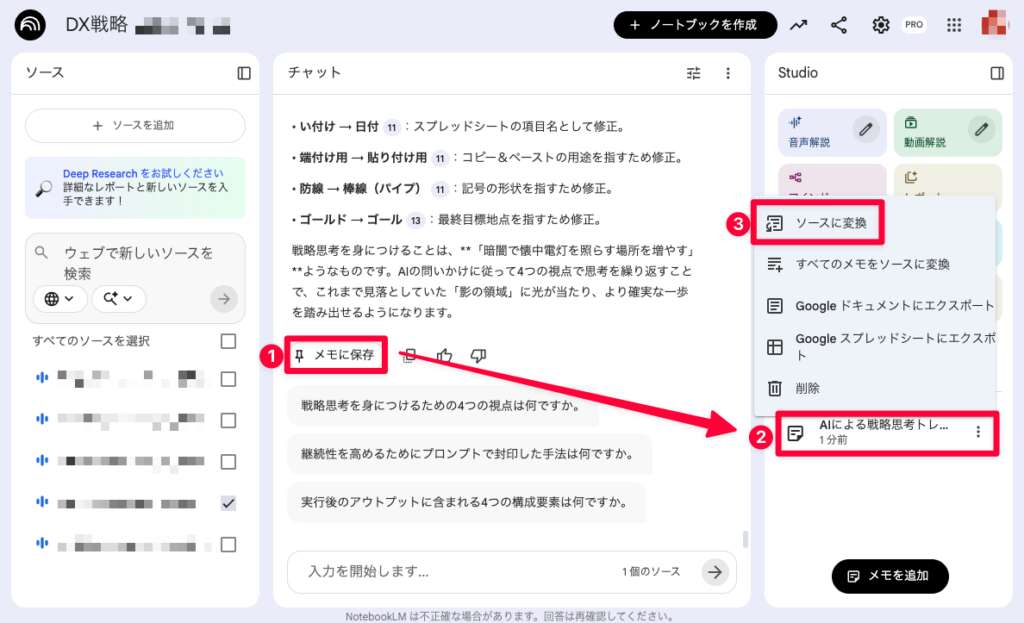
2-1. 整形済みテキストをメモとして保存
まずは、整形結果を「メモ」として保存しましょう。
メモ名は、後から見たときに分かりやすいように付けておくと良いですね。
メモ名の例:
2025-01-10_開発定例_整形済み文字起こし2025-01-15_ユーザーインタビュー#3_整形済み文字起こし
こうしておくと、ノートブック内で「あの会議の議事録、どこだっけ?」とググる必要がなくなります。
2-2. メモをソースに変換する
次に、そのメモを「ソース」として登録します。
NotebookLMのUIには「ソースに変換」といったボタンがあるので、そこから簡単に変換できます。
これをやっておくと、NotebookLMに対して、
- 「この会議の決定事項だけを箇条書きにして」
- 「このインタビューから、ユーザーの不満点だけをリストアップして」
- 「この講演で語られているキーメッセージを3つに絞って」
といった質問に対して、より正確に回答が返ってくるようになります。
つまり、
- 音声 → 自動文字起こし(生テキスト)
- 生テキスト → 整形済みテキスト
- 整形済みテキスト → ソース化してQ&A・要約・タスク抽出に活用
という3段階で、「一度録った音声から、何度も価値を取り出せる」状態になります。
2-3. 元の生文字起こしはどうする?
ここで、よくある質問があります。
「元の生文字起こしは、削除していいんですか?」
ノートブック内に「生の文字起こし」と「整形済み」が両方あると、散らかりがちなんですね。
私のおすすめの運用は、こうです。
- ノートブック内には「整形済み」だけを残す
- 生の文字起こしが不安なら、ローカルにバックアップしてからNotebookLMからは削除
こうしておくと、「どのテキストが正式版か」で迷わなくなります。
3. NotebookLM文字起こし整形術の注意点
さて、ここまで説明してきましたが、実際に使ってみると「あれ?」となるポイントが2つあります。
皆さんが同じところでつまずかないよう、先に共有しておきますね。
3-1. 要約させないと、勝手に短くされがち
NotebookLMは、生成AI(ジェネレーティブAI)の中でも「要約が得意」なツールです[1]。
ですから、「整形して」とだけ書くと、内容を削ってしまうことがあるんですね。
毎回プロンプトに、
- 「要約しない」
- 「情報を削らない」
- 「元の発言内容をできるだけ残したまま」
といったフレーズを入れておくと、安全です。
要約版が欲しいときは、「整形が終わったテキスト」を別のプロンプトで要約させる、という二段構えにすると良いと思います。
3-2. タイムスタンプや完全な話者分離は苦手
もう1つ、NotebookLMの限界として知っておいていただきたいのが、「タイムスタンプ」の扱いです。
NotebookLMは、音声の「何分何秒の発言か」までは理解していません。
ですから、タイムスタンプ付きの議事録が必要な場合は、
- 文字起こしツール側でタイムスタンプ付きテキストを出す
- NotebookLMには、そのタイムスタンプを壊さない範囲で整形を依頼する
といった工夫が必要になります。
また、話者ラベルも「声」ではなく「テキスト内容」からの推測なので、重要な会議の音声メモなどでは最終的に人間が確認する前提で使ってください。
4. まとめ:まずは1本、試してみてください
ここまで、お疲れさまでした。
説明ばかりで退屈だったかもしれませんが、実際にやってみると意外と簡単ですよ。
ポイントをまとめると、こうなります。
- NotebookLMで音声から自動文字起こしを作ったら、そのまま使わず「整形」までやると一気に実用的になる
- プロンプトには、「誤字脱字修正」「句読点・改行の整形」「(会議なら)参加者情報+話者ラベル」「固有名詞の表記統一」「要約しない・情報を削らない」をセットで書く
- 気に入った整形結果はメモ&ソース化しておけば、決定事項の抽出や要約など、あとから何度でも活用できる
まずは直近の会議音声を1本だけNotebookLMに入れて、この整形フローを試してみてください。
きっと、「こんなに楽になるのか!」と感じていただけると思います。
よくある質問(FAQ)
Q1. 無料版のNotebookLMでも、ここまでの整形はできますか?
はい、できます。基本的なソース追加・チャット・メモ機能は、無料版でも利用可能です。
ただし、無料版はアップロードできるソース数や使用量に制限があります。
また、有料版・無料版ともに200MBの容量制限があるので、動画などの場合は音声にしてからソース化する必要があります。
Q2. 会議以外にも、この整形術は使えますか?
もちろんです。オンライン講義、ウェビナー、ポッドキャスト、YouTube動画の音声など、NotebookLMが文字起こしできる音声・動画であれば、同じ手順で整形できます。
顧客インタビューの音声をこの方法で整形して、自身のプロジェクトに活用している事例もあります。
Q3. 話者ラベルの精度は、どのくらい期待していいですか?
NotebookLMは声を識別しているわけではなく、「発言内容」や「ソース内の情報」から推測しているだけです。
ですから、「だいたい誰が話しているか分かる」程度と考えていただくのが良いと思います。
重要な会議では、人間が最終チェックする前提で使うのがおすすめです。
Q4. 機密性の高い会議の音声を、NotebookLMにアップロードしても大丈夫ですか?
これは、ご自身の組織の情報セキュリティポリシーによります。
NotebookLMはアップロードしたソースを元に回答を生成しますが、Googleはユーザーのコンテンツをモデルのトレーニングには使用しません。
ただし、社内ルールを確認したうえで判断してください。特に顧客名や個人情報が多い場合は、加工してからアップロードする運用も検討すると良いと思います。
Q5. 他のノートアプリ(NotionやObsidianなど)とどう使い分ければいいですか?
NotebookLMは「ソースに基づくAI対話」と「自動文字起こし・整形」に強みがあります。
一方で、日々のメモ管理やWiki構築は、NotionやObsidianの方が得意です。
おすすめの使い分けは、「音声→文字起こし→整形→要約・タスク抽出」まではNotebookLMで行い、その結果だけを他のノートアプリに貼る、という役割分担です。
こうすることで、それぞれのツールの良いところを活かせると思います。
最終更新日:2025年1月12日
※免責事項
本記事の情報は執筆時点のものです。AI技術は急速に進歩しているため、最新情報については各サービスの公式サイトをご確認ください。
Citations:
[1] https://notebooklm.google/ – Google NotebookLM公式サイト
[2] https://support.google.com/notebooklm/?hl=en – NotebookLM公式ヘルプセンター
[3] https://support.google.com/notebooklm/answer/16262519?hl=en – メモ(notes)機能の使い方
[4] https://workspace.google.com/products/notebooklm/ – Google Workspace版NotebookLM
[5] https://blog.google/innovation-and-ai/models-and-research/google-labs/notebooklm-deep-research-file-types/ – NotebookLM機能アップデート情報




生成AI・IT活用の初心者向け解説を得意とするWebライター。
商品開発や業務効率化のコンサルタントとして10年以上の活動を行い、現在は中小企業のデジタル活用支援や、AIツールの導入・教育コンテンツ制作を多数手がける。DX研修の受講者数は100名を優に超える。
「難しい技術を、やさしく・わかりやすく」をモットーに情報発信中。








